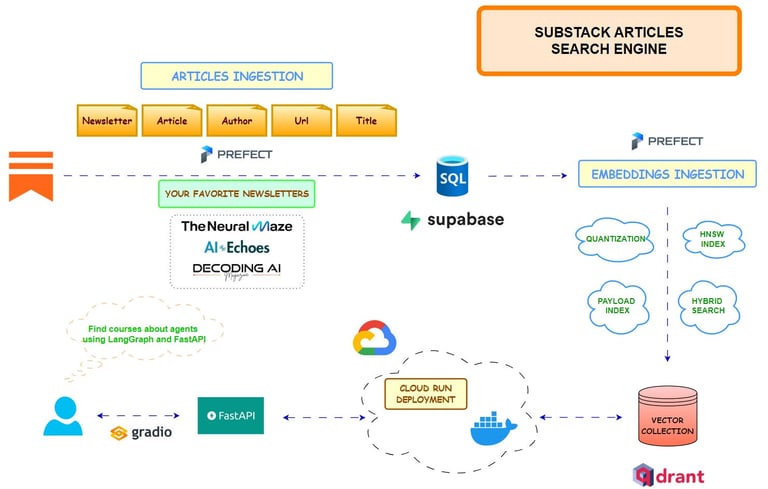
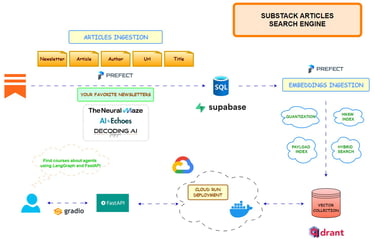
Publishing Platforms
Articles covering topics such as Data Science, Machine Learning, and AI, including end-to-end applications, large language models (LLMs), Retrieval-Augmented Generation (RAG), and optimization techniques.













My technical writing has been featured in major industry newsletters and platforms, such as LlamaIndex Newsletter, GKE Newsletter, and the MLOps Community.